
Bonjour à tous !
C’est la rentrée ! Nous sommes en Septembre ! Et pour bien commencer, je vous propose de faire un petit rappel sur ce qu’est le Big Data … ou plutôt quels sont les éléments principaux qui le constituent.
En effectuant ma veille automatisée avec mon logiciel de veille, je suis tombée sur une infographie qui démontre, de façon plus ou moins vulgarisée, les 4 principaux pilliers du Big Data.
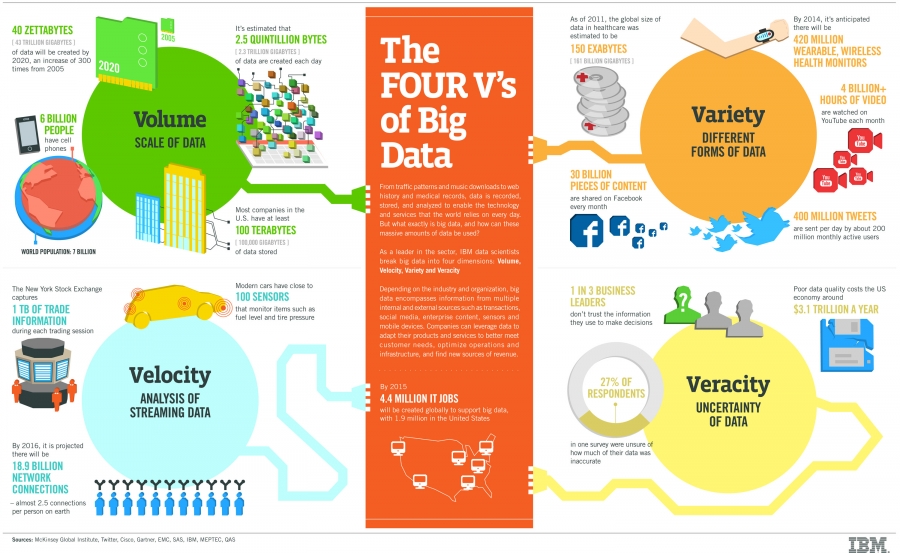
Le Big Data se définirait par la règle des 4V : Volume, Variété, Véracité et Vélocité (Vitesse)
Je profite également de cet article pour donner une définition complète et détaillée du Big Data (une définition provenant du site d’IBM) :
Le Big Data se présente sous la forme de données structurées ou non structurées (texte, données de capteurs, son, vidéo, données sur le parcours, fichiers journaux, etc.). De nouvelles connaissances sont issues de l’analyse collective de ces données.
Les entreprises sont submergées de volumes de données croissants de tous types, qui se comptent en téraoctets, voire en pétaoctets. Le Big Data va bien au-delà de la seule notion de volume : il constitue une opportunité d’obtenir des connaissances sur des types de données et de contenus nouveaux, afin de rendre votre entreprise plus agile et de trouver enfin une réponse aux questions laissées en suspens.
D’après cette définition, le Big Data équivaut à tout ce que l’on trouve sur le web. En tout cas, c’est ma vision des choses. Chaque information, chaque vidéo, constitue une petite partie du Big Data. En veillant de façon régulière sur cette masse de données, les particuliers et les entreprises peuvent en apprendre de plus sur leurs domaines et affiner leurs stratégies. C’est pourquoi, il faut absolument gérer, classer, analyser ces données, ces informations.
Voici l’infographie sur les 4 pilliers du Big Data, réalisée par IBM :
 Actuellement, aucun logiciel n’est encore capable de gérer toutes ces données sur le web. En plus de cela, il faut encore prendre en compte les données « cachées » dans le web profond ou le web invisible qui pourraient être encore plus difficile à récupérer. Les problématiques du Big Data font partie de notre quotidien, et il faudrait des solutions de plus en plus avancées pour gérer la masse de données qui ne cesse d’augmenter.
Actuellement, aucun logiciel n’est encore capable de gérer toutes ces données sur le web. En plus de cela, il faut encore prendre en compte les données « cachées » dans le web profond ou le web invisible qui pourraient être encore plus difficile à récupérer. Les problématiques du Big Data font partie de notre quotidien, et il faudrait des solutions de plus en plus avancées pour gérer la masse de données qui ne cesse d’augmenter.
Bon courage à tous !
Véronique Duong –
