
Bonjour tout le monde !
Aujourd’hui, je vous ai préparé un article qui va toucher deux disciplines qui sont étroitement corrélées, à savoir le traitement automatique des langues (ou ingénierie linguistique) et le référencement naturel (ou SEO).
Ce que vous allez lire par la suite ne sont que des hypothèses car je ne connais pas l’algorithme de Google, mais après de nombreux tests, je trouve qu’il y a de (fortes) similitudes qui existent entre la méthode que j’utilise pour retrouver des pages web ou des fichiers dans mon système et celle du moteur de Google.
En effet, j’utilise souvent l’aspiration de sites web pour stocker les pages web qui m’intéressent, et pour en retrouver certaines, j’utilise des mots-clés … comme des requêtes que les internautes taperaient sur Google !
Voici l’exemple de mon propre site ci-dessous. Comme vous pouvez le voir, les pages web / HTML, les images, les autres fichiers sont tous crawlés par mon logiciel de crawling (qui n’est autre que mon logiciel de veille détourné en outil de crawl) :

Ensuite, pour trier les pages HTML que j’ai dans ma base ci-dessus, je lance une requête (encadrée en vert) de ce genre dans ma Konsole :
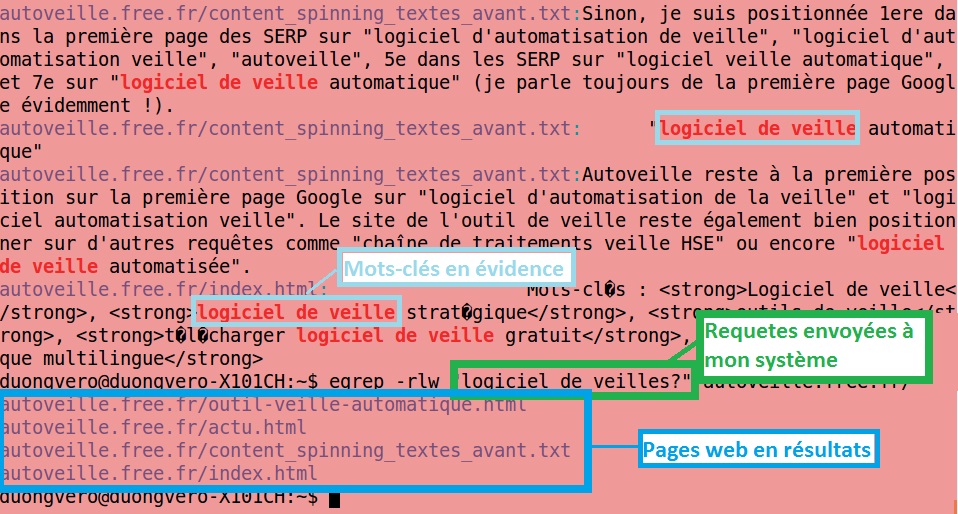
Je pense que Google posséderait une base de données gigantesque au vu du nombre de pages web qui existent, et des milliers de corpus thématiques / catégoriques. A chaque requête tapée, Google essayerait de fournir la meilleure réponse à l’utilisateur parmi ses trilliards de pages HTML 🙂
Je précise également que mon outil de crawl / de veille ne lit et ne crawl pas les images, le JavaScript. En tout cas, il y a des choses extrêmement corrélées entre le TAL et le SEO, et je m’éclate en faisant des recherches, des tests dans ces deux domaines ! 🙂
Très prochainement, je vous montrerai comment faire du content spinning propre !
Bon courage à tous,
Véronique Duong –
