Bonsoir !
J’ai décidé de poster un petit article sur Lexico 3, un outil de lexicométrie / textométrie fournissant des statistiques textuelles développé par l’Université Sorbonne Nouvelle.
Il y a deux ans (pratiquement jour pour jour !), je me suis servie de cet outil pour faire des analyses sémantiques (style « journalistique » et style « conversations en ligne » sur les forums, blogs, etc.), et cela avait bien marché. Les spécificités positives, négatives, statistiques textuelles sont précises, et permettent de faire de bonnes analyses.
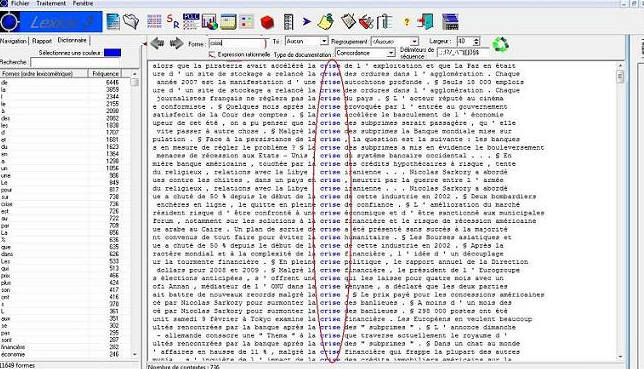
Par exemple, pour le style « conversations en ligne », j’ai travaillé sur les contenus textuels du site communautaire Samestory. Il fallait catégoriser les verbatims en positif / neutre / négatif à l’aide de Lexico 3 (concordances / collocations / coocurrences). Vous remarquerez que les textes sont effectivement classés par tonalité dans le site:

Lexico 3 nous offre la possibilité d’avoir un outil de concordance pour identifier tous les contextes où chaque mot-clé qu’on aura déterminé se trouve. Un mot positif dans un contexte négatif a une tonalité négative, et vice-versa. Il faut également faire attention aux textes avec un ton ironique, humoristique, les sous-entendus, etc.
C’est pour cela que nous avons besoin d’analyser les contextes.

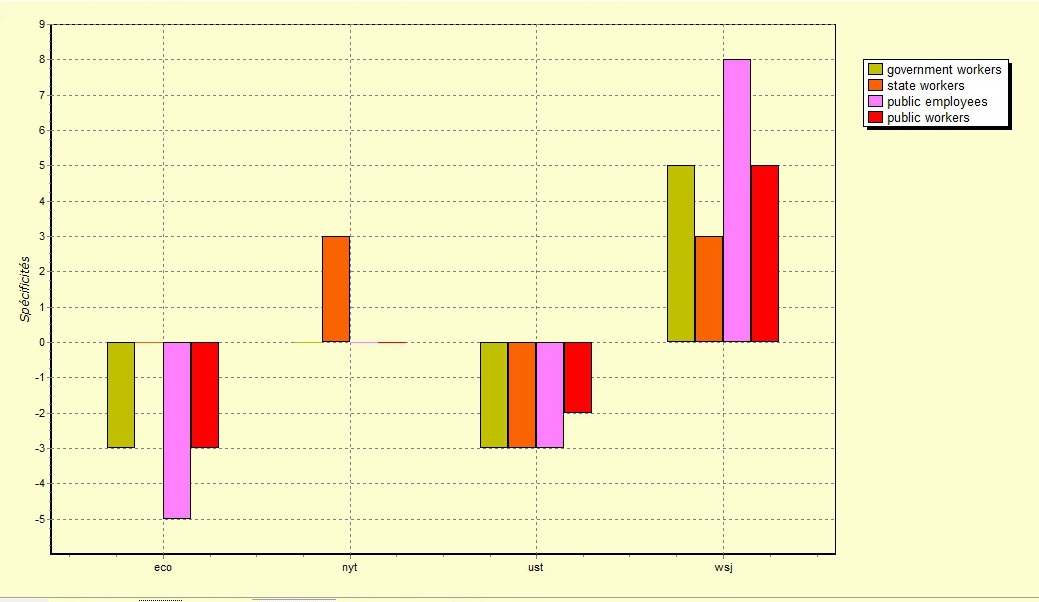
De plus, pour mesurer la présence d’un mot dans les contenus textuels, on peut utiliser les statistiques textuelles, et en former des graphes ou des histogrammes. La version histogramme est plus claire à mon goût car on voit tout de suite si un mot est plus présent dans une thématique par rapport à une autre, ou selon votre catégorisation:

En tout cas, cet outil est utile pour faire de l’analyse sémantique reposant sur des statistiques textuelles. Je l’utilise également pour faire de l’analyse d’opinions.
La prise en main peut être un peu technique au début, mais on s’habitue très vite (si on l’utilise régulièrement). Lexico 3 prend un certain format de balises dans le corpus.txt à mettre en entrée.
Si vous voulez en savoir plus, je peux vous expliquer plus en détails avec les études que j’ai faites.
Bon courage 🙂
Véronique Duong

 Si vous souhaitez en savoir plus, je vous invite à vous rendre sur le site AUTOVEILLE pour avoir plus d’informations. Sinon, posez-moi des questions via autoveille@gmail.com
Si vous souhaitez en savoir plus, je vous invite à vous rendre sur le site AUTOVEILLE pour avoir plus d’informations. Sinon, posez-moi des questions via autoveille@gmail.com