
Bonjour à tous !
J’ai récemment développé une nouvelle petite technique pour extraire toutes les balises title d’un site web en quelques secondes ! Cette nouvelle fonctionnalité va également rejoindre le package d’outils SEO d’AUTOVEILLE.
Pour faire cette extraction, j’ai eu besoin de « détourner » AUTOVEILLE Monitoring (le logiciel de veille) en tant qu’outil de crawl pour collecter toutes les pages du site web. A la suite de la récupération automatique des pages web du site, je lance ma règle d’extraction sur cette collecte pour n’extraire que les informations dont j’ai besoin : ici, les balises title.
J’ai pris le site d’Oliver Duffez pour faire le test :
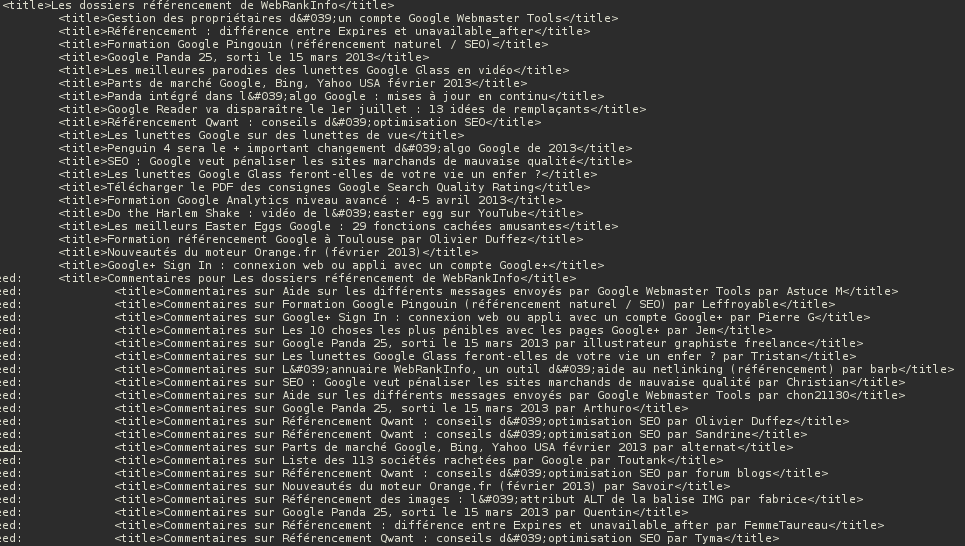
1) Voici la première extraction brute, sans nettoyage
2) Après quelques lignes de commandes lancées dans la Konsole de Kubuntu pour le nettoyage :
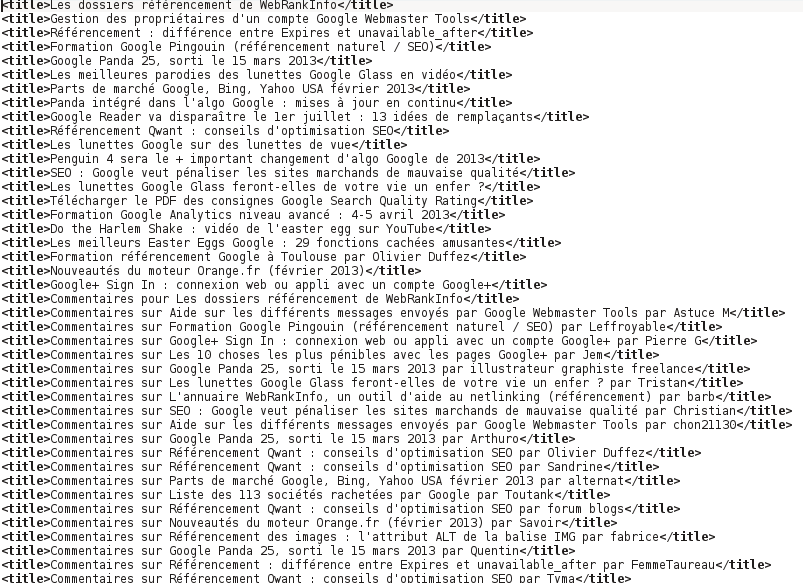
En tout, l’extraction a duré moins de 2 secondes … mais dépendant de la taille du site, le temps d’extraction pourrait varier. On peut utiliser cette extraction de balises title pour vérifier la longueur de ces dernières, les mots-clés, etc. Très pratique dans l’ensemble.
Peu à peu, j’utilise de moins en moins Xenu ou autres outils de ce type pour faire les crawls, car je trouve qu’ils sont moins souples et personnalisables par rapport à AUTOVEILLE qui est composé d’outils codés essentiellement en Perl (mais pas que !).
En tout cas, si vous voulez tester la fonctionnalité d’extraction complète d’URL de site web (crawl) et/ou l’extraction de balises title, contactez-moi ! 🙂 Il se peut que j’ouvre une nouvelle session de tests, très bientôt, pour le SEO aussi. Les tests sont fait pour vous faire découvrir l’ingénierie linguistique / le traitement automatique des langues (ou des données plutôt), et ils ne sont pas payants.
Bon courage à tous !
Véronique Duong –
