
Bonjour à tous,
Comme on me le demande souvent, j’ai décidé de faire un article pour vous montrer comment faire une veille automatique ainsi qu’une collecte automatique des tweets depuis Twitter.
Pour cela, je développe un script Perl pour chaque crawl. C’est à dire que j’adapte mes crawls en fonction du type d’éléments à crawler. Récupérer des tweets est différent de récupérer des pages web par exemple.
A partir d’une recherche de tweets par #hashtag, mot-clé ou expressions clés, j’en crée un flux RSS que je passe sous AUTOVEILLE. Ensuite, mon logiciel de veille collecte les tweets au format XML, et je traite ce XML au format demandé par le client.
Voici un exemple d’un tweet au format XML:
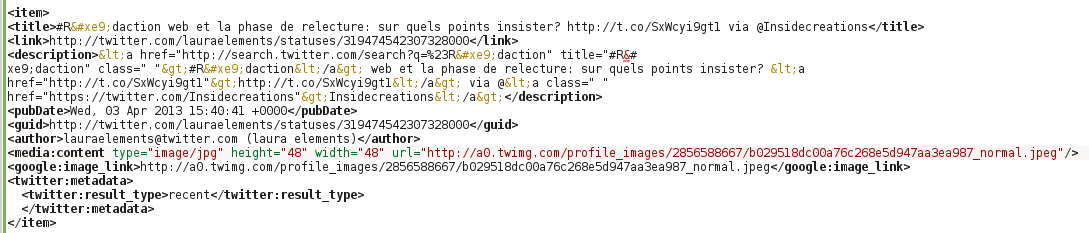
Avec quelques lignes de commandes Bash (Shell), je récupère uniquement les liens vers mes tweets collectés:
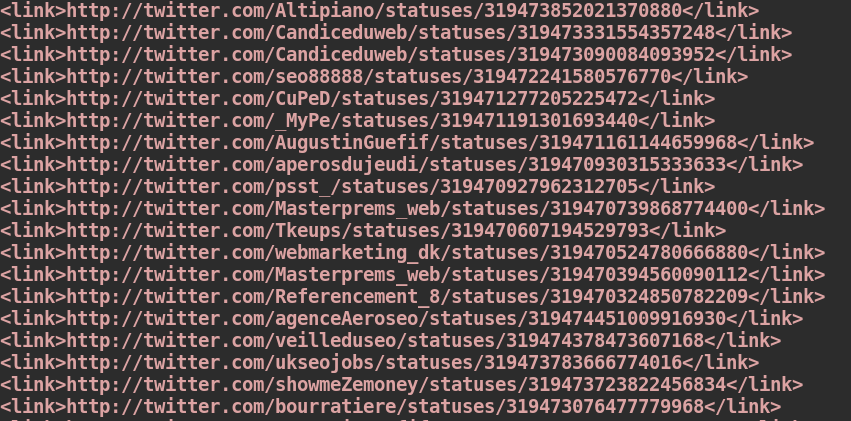
Encore un peu de nettoyage automatique pour retirer les balises link

Voilà, avec cette collecte, vous pouvez sauvegarder vos précieux tweets. Pour les afficher, il suffit de les repasser au format XML ou HTML. En repassant au format HTML, on obtient des tweets dans ce format:

J’adapte chaque veille / chaque collecte au cas par cas comme vous pouvez le constater.
Bon courage !
Véronique Duong –

