Bonjour à tous,
Pour faire suite à la publication de mon article précédent sur mon nouvel outil SEO (sur l’extraction automatique de balises title), j’ai effectué un test sur un site chinois qui est apparu parmi les premiers résultats dans la première SERP de Baidu.
Je voulais voir quels sites web apparaîtraient dans la première page de résultats naturels de Baidu avec un mot-clé ultra générique comme « 皮包 » (sac en cuir).
Baidu priorise bien évidemment ses propres services … bien plus que Google comme vous pourriez le constater. Je différencie donc les résultats provenant du nom de domaine baidu.com des autres sites web :

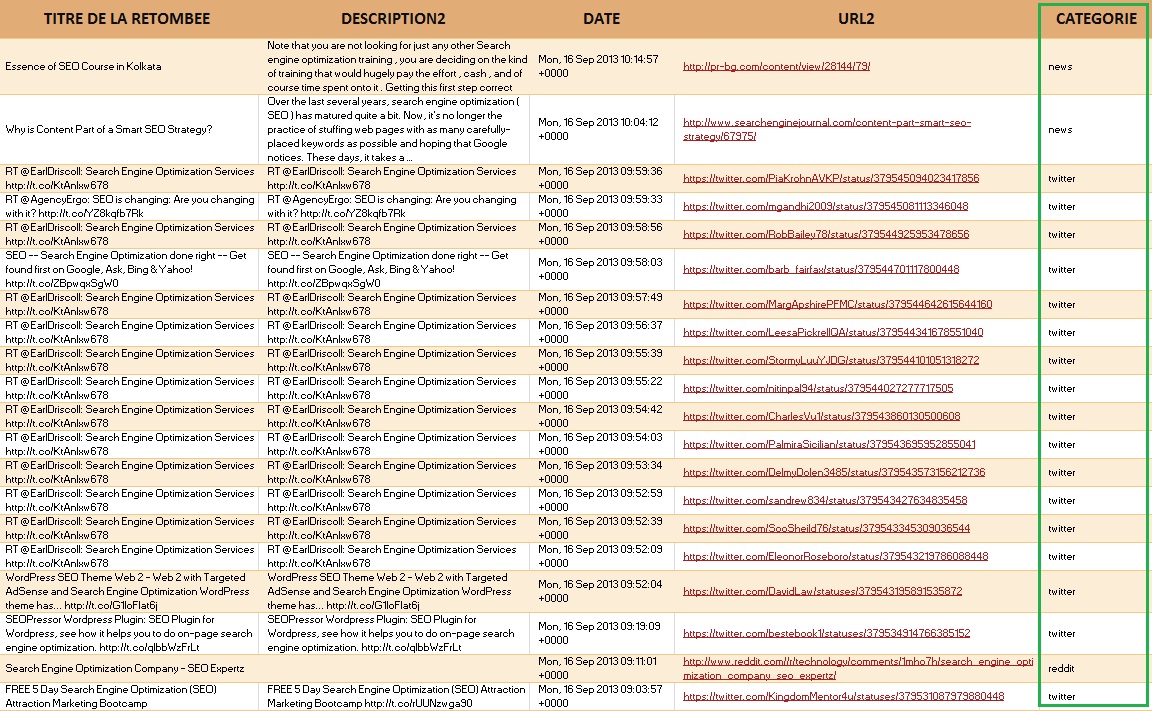
Celui qui m’a intéressé parmi les trois sites encadrés en vert, et le résultat http://www.bag86.com. (La date qui suit, est la date du dernier crawl de Baiduspider).
Pourquoi ? Le nom de domaine de http://www.bag86.com ne contient aucun mot chinois en pinyin, mais juste un mot anglais ultra, méga générique, « bag » suivi de « 86« , et il est très bien classé avec « 皮包 » (sac en cuir) sur Baidu. C’est la page d’accueil qui est très bien placée ici.
J’ai donc voulu en savoir plus en lançant quelques petites analyses sur cette page d’accueil et les title du site bag86.com.
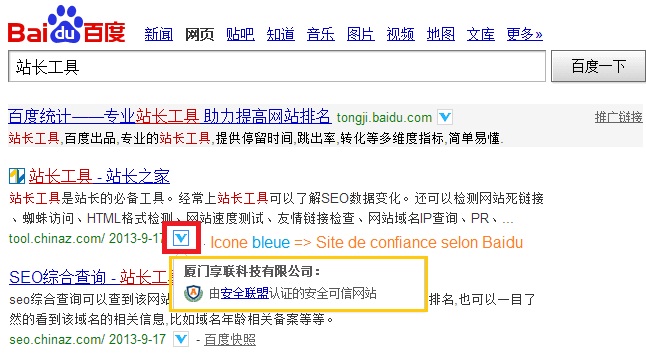
Baidu m’indique que la page d’accueil de bag86.com n’est pas tout à fait optimisée … il y a une bonne moitié des éléments qui ne sont pas « valides » pour le moteur de recherche chinois (cliquez sur l’image pour agrandir) :

Cependant, ces éléments auraient une importance plus minime car ils concernent essentiellement les attributs ALT, le CSS, le JavaScript, les images, qui ralentissent surtout le temps de chargement du site.
Baidu accorde une grande importance dans ces « recommandations » sur le JavaScript et le Flash car il ne les indexe pas du tout (contrairement à Google qui commencerait à indexer des contenus Flash).
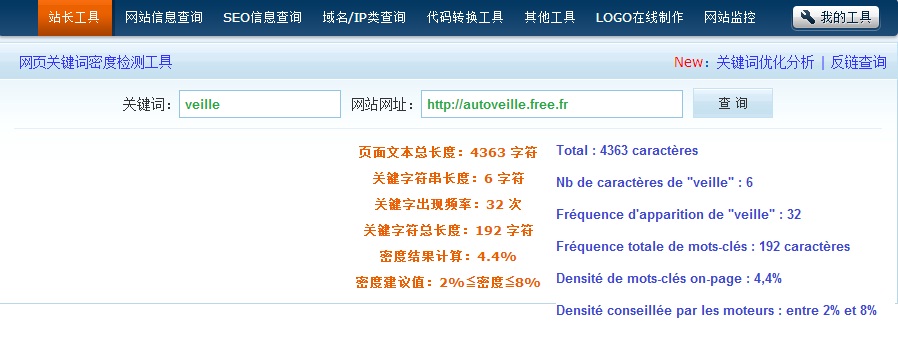
En revanche, bag86.com a bien optimisé le reste (pas de Flash, etc.), ses meta tags, et surtout ses balises title selon Baidu :

Les méta tags de http://www.bag86.com restent conformes aux règles des moteurs de recherche chinois car elles ne dépassent pas la limite de caractères et comportent des mots-clés :

La dernière fois que ces méta ont été mis à jour date du 10 juillet 2012.
Pour bien comprendre comment la page d’accueil peut être si bien positionnée … j’ai finalement procédé à l’extraction automatique de toutes les balises title du site. J’ai lancé un simple Ctrl+F pour vous montrer le nombre de fois que le mot-clé « 皮包 » est répété :
 Pour chaque title, le mot-clé est au moins répété 2 fois (en moyenne). Il est également répété dans les balises méta keywords et méta description. Pour Google, ça serait de la sur-optimisation absolue !!
Pour chaque title, le mot-clé est au moins répété 2 fois (en moyenne). Il est également répété dans les balises méta keywords et méta description. Pour Google, ça serait de la sur-optimisation absolue !!
Baidu prend également en compte le Page Rank. La page d’accueil bag86.com est très populaire (PR 4), et cela permettrait de comprendre pourquoi il est aussi bien classé dans la première SERP de Baidu.
Voilà, j’espère que cette analyse vous aurait appris quelque chose de plus sur Baidu ! 🙂
Bon courage à tous,
Véronique Duong –