Bonjour à tous,
Dans l’article d’aujourd’hui, nous nous intéressons aux systèmes et aux méthodes d’indexation et de référencement de Google. En effectuant une veille stratégique sur les algorithmes de Google, mon logiciel de veille m’a rapatrié un article très intéressant portant sur le fonctionnement des crawlers et des différents autres composants de Google. Cet article a été rédigé par les deux fondateurs de Google, Sergey Brin et Larry Page. Vous pouvez lire cet article en suivant le lien sur le site de Stanford.edu
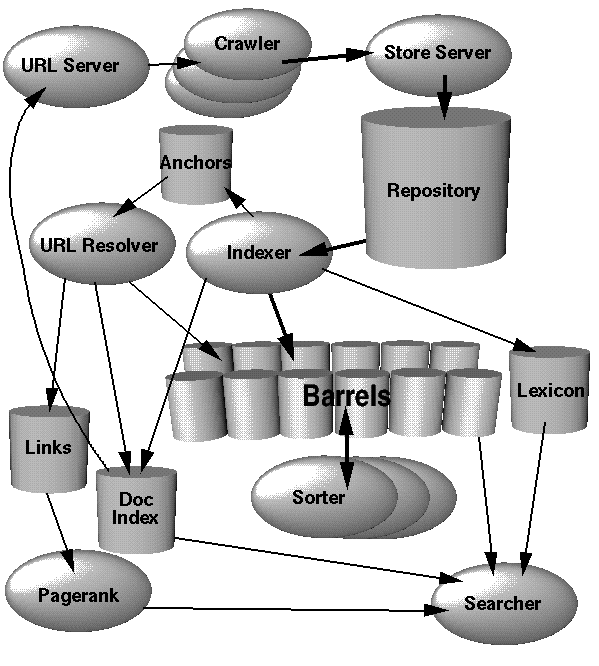
Même si les algorithmes du moteur sont confidentiels, grâce au schéma fourni dans l’article, on peut tout de même mieux comprendre comment marche l’indexation chez Google. Dans le livre d’Olivier Andrieu, on peut lire que Google posséderait deux index : un index principal (où il faut absolument y être pour être visible) et un index secondaire (pages dupliquées, pages ayant peu de liens externes, pages « mal liées », etc.).
Voici l’architecture « high level » (comme le décrit les fondateurs) de Google :

Source : Stanford (Article rédigé par Sergey Brin et Larry Page)
Voici ce que les fondateurs expliquent par rapport à cette structure [Extrait de l’article] :
In Google, the web crawling (downloading of web pages) is done by several distributed crawlers. There is a URLserver that sends lists of URLs to be fetched to the crawlers. The web pages that are fetched are then sent to the storeserver. The storeserver then compresses and stores the web pages into a repository. Every web page has an associated ID number called a docID which is assigned whenever a new URL is parsed out of a web page. The indexing function is performed by the indexer and the sorter. The indexer performs a number of functions. It reads the repository, uncompresses the documents, and parses them. Each document is converted into a set of word occurrences called hits. The hits record the word, position in document, an approximation of font size, and capitalization. The indexer distributes these hits into a set of « barrels », creating a partially sorted forward index. The indexer performs another important function. It parses out all the links in every web page and stores important information about them in an anchors file. This file contains enough information to determine where each link points from and to, and the text of the link.
The URLresolver reads the anchors file and converts relative URLs into absolute URLs and in turn into docIDs. It puts the anchor text into the forward index, associated with the docID that the anchor points to. It also generates a database of links which are pairs of docIDs. The links database is used to compute PageRanks for all the documents. […]
Pour résumer en français, le crawling est effectué par différents robots. Il y a un « URLserver » qui envoie une liste d’URLs à extraire aux crawlers. Ces URLs seront ensuite envoyées dans le « storeserver ». Puis le storeserver compresses et stockes les pages web (URLs) dans un « entrepôt ». Chaque page a un ID nommé docID qui lui est assignée.
L’index fonctionne grâce à deux composants : l' »indexer » et le « sorter » (outils d’indexation et de tri). L’indexer possède plusieurs fonctions. Il lit les éléments dans l’entrepôt, décompresse les documents et les décrypte. Chaque document est découpé en mots nommés « hits ». L’indexer met ces « hits » dans des silos (« barrels »), ce qui crée des index partiellement triés. L’indexer analyse tous les liens d’une page et stocke les ancres dans un fichier nommé « anchors ». Ce fichier contient des informations qui indiquent d’où provient un lien et le texte sur ce lien (l’ancre).
L’URLresolver lit les fichiers d’ancres et convertit les liens relatifs en liens absolus qui sont ensuite transformés en docIDs. Cela met l’ancre de texte dans l’index transféré, associé au docID dont l’ancre y pointe. Cela génère également une base de données de liens qui est utilisée pour calculer le PageRank de chaque page … 🙂
Grâce à cet article, on comprend bien mieux comment Google fonctionne. Il n’y a pas qu’un outil, qu’un seul algorithme, mais plusieurs qui tournent en même temps. Panda, Penguin, etc. ne seraient rien d’autres que des composants qui font partie de la chaîne de traitements maintenant. Je n’ai traduit que l’essentiel de l’article car c’est la partie la plus intéressante pour comprendre le SEO à mon avis. En voyant le schéma, c’est typiquement une chaîne de traitements d’ingénierie linguistique informatique très poussée. Peu à peu, je vais me remettre dans les recherches scientifiques car j’aime beaucoup étudier les problématiques liées à ce domaine.
Si vous avez des questions sur le traitement automatique des données ou le référencement naturel, n’hésitez pas à me contacter avec cette adresse autoveille@gmail.com
Bon courage à tous !
Véronique Duong –

 Cet article s’adresse aux sociétés qui estiment encore que le web marketing et/ou le mobile marketing sont secondaires. Vous pouvez lire à quel point vous pouvez augmenter vos visites, vos ventes, rentabiliser vos stratégies marketing grâce aux médias digitaux (vs. aux médias traditionnels).
Cet article s’adresse aux sociétés qui estiment encore que le web marketing et/ou le mobile marketing sont secondaires. Vous pouvez lire à quel point vous pouvez augmenter vos visites, vos ventes, rentabiliser vos stratégies marketing grâce aux médias digitaux (vs. aux médias traditionnels).