Bonjour tout le monde,
En effectuant ma veille stratégique sur les informations liées au référencement naturel avec mon logiciel de veille, je suis tombée sur une infographie portant sur le Negative SEO. Jusqu’à présent, sur ce blog, je n’ai jamais encore traité ce sujet qui est pourtant un vrai problème. En effet, je n’ai jamais rédigé d’articles sur cela car ce genre de cas reste assez rare (mais ils existent). Personnellement, je n’ai pas encore rencontré de cas de negative SEO, et de ce fait, l’idée de parler de quelque chose que je ne connais pas et n’ai pas vécu, me paraissait peu concret.
Cependant, en lisant l’infographie ci-dessous, je me suis dit que je pourrais la partager avec vous, mes lecteurs !
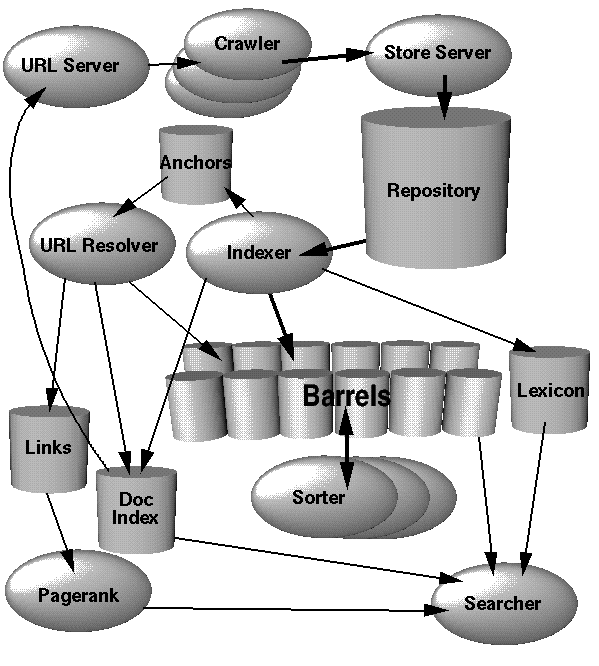
Alors, qu’est ce le Negative SEO ? D’après la définition de l’infographie, ce terme est utilisé pour désigner des pratiques et des techniques black hat non éthiques pour « saccager » les positionnements d’un site (concurrent) dans les résultats de recherche.
Voici quelques exemples de ces techniques :
- Hacker le site d’un concurrent dans le but de le faire disparaître des (premières) pages de Google
- Créer des faux profils sur les réseaux sociaux pour détruire l’e-réputation d’un concurrent
- Créer des milliers de liens spam ou de mauvaise qualité vers un site
- Copier le contenu original d’un site et le poster en spammant partout sur le web
Selon moi, ces techniques sont lamentables et « criminelles » pour un site web. Et tôt ou tard, les auteurs se feront punir sévèrement par Google ou encore mieux … par la justice. Par exemple, en mai 2014, on pouvait lire ce cas sur le site Abondance d’Olivier Andrieu. Il faut donc se trouver des moyens pour se protéger de ces attaques. Toujours dans la même illustration, on y trouve quelques conseils intéressants :
- Mettre en place les Google Webmaster Tools (en 2014, il y a encore des sites ou des personnes qui se disent « responsables SEO » qui ne les connaissent ou ne les utilisent pas !)
- Mettre en place des alertes de veille (Google Alerts ou autres outils de veille)
- Surveiller les commentaires et les avis sur vous dans les réseaux sociaux (Twitter, Facebook, Google+, etc.)
- Surveiller vos liens externes (Majestic SEO, Ahrefs, etc.)
- Protéger les contenus originaux du plagiat avec des outils comme Copyscape
Cette infographie a été réalisée en 2014 par TECHMAGNATE :

Les sites victimes de Negative SEO pourraient de plus être pénalisés par Google comme le cas indiqué dans l’illustration. Avant d’être pénalisé, le site était bien positionné sur des mots-clés ultra génériques comme « online songs« , « online music« , etc. Après la pénalité, les positionnements du site ont fortement dégringolé. L’agence TECHMAGNATE a sorti le site de la pénalité après 2 mois et demi de travail, mais on constate qu’il n’a pas (encore ?) retrouvé ses excellents classements d’avant (en première page Google).
Avez-vous déjà rencontré ce problème de Negative SEO ? Qu’avez-vous fait pour « sauver » les sites qui en ont été victimes ? N’hésitez pas à partager votre expérience avec mes lecteurs et moi dans l’espace des commentaires ci-dessous 🙂
Merci et bon courage à tous !
Véronique Duong –